Why did git push so much data? -
i'm wondering git doing when pushes changes, , why seems push way more data changes i've made. made changes 2 files added around 100 lines of code - less 2k of text, i'd imagine.
when went push data origin, git turned on 47mb of data:
git push -u origin foo counting objects: 9195, done. delta compression using 4 threads. compressing objects: 100% (6624/6624), done. writing objects: 100% (9195/9195), 47.08 mib | 1.15 mib/s, done. total 9195 (delta 5411), reused 6059 (delta 2357) remote: analyzing objects... (9195/9195) (50599 ms) remote: storing packfile... done (5560 ms) remote: storing index... done (15597 ms) <<redacted>> * [new branch] foo -> foo branch foo set track remote branch foo origin. when diff changes, (origin/master..head) 2 files , 1 commit did show up. did 47mb of data come from?
i saw this: when "git push", statistics mean? (total, delta, etc.) , this: predict how data pushed in git push didn't tell me what's going on... why pack / bundle huge?
when went push data origin, git turned on 47mb of data..
looks repository contains lot of binaries data.
first let's see git push does?
git-push- update remote refs along associated objects
what associated objects?
after each commit git perform pack of data files named xx.pack && `xx.idx'
a reading packing here

how git pack files?
the packed archive format
.packdesigned self-contained can unpacked without further information.
therefore, each object delta depends upon must present within pack.a pack index file
.idxgenerated fast, random access objects in pack.placing both index file
.idx, packed archive.packinpacksubdirectory of$git_object_directory(or of directories on$git_alternate_object_directories) enables git read pack archive.
when git pack files in smart way fast extract data.
in order achieve git use pack-heuristics looking similar part of content in pack , storing them single one, meaning - if have same header (license agreement example) in many files, git "find" , store once.
now files include license contain pointer header code. in case git doesn't have store same code on , on pack size minimal.
this 1 of reasons why it's not idea , not recommended store binary files in git since chance of having similarity low pack size not optimal.
git store data in zipped format reduce space again binary not optimal whcn zipped (size wize).
here sample of git blob using zipped compression:
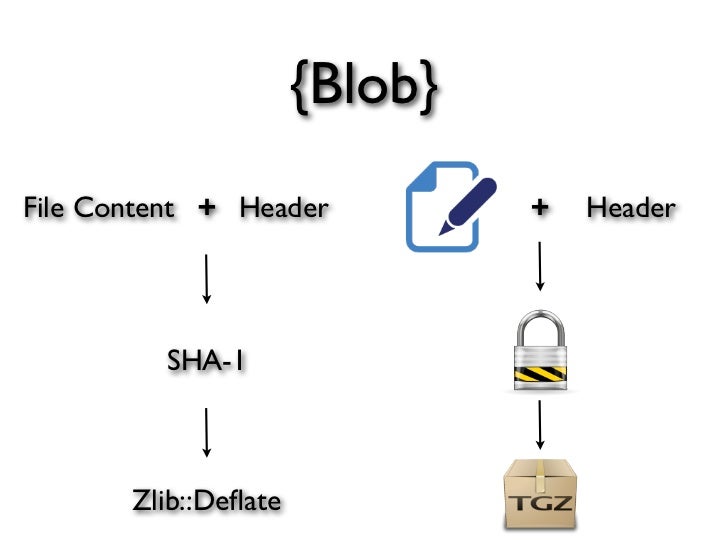

Comments
Post a Comment